
Nell’articolo precedente abbiamo iniziato a studiare come funziona il client del lettore di presenze, andando anche a decompilarne l’eseguibile. In questo articolo vorrei cercare di comprendere il protocollo di comunicazione che il client usa per interfacciarsi col lettore.
I motivi per cui non ho fatto subito il reverse engineering del protocollo sono sostanzialmente due:
-
Se fossi riuscito a decompilare correttamente il codice dell’eseguibile avrei potuto creare un client alternativo con molta più semplicità;
-
A volte non si può eseguire (almeno in modo semplice) lo sniffing di una comunicazione per via del TLS.
Purtroppo però la decompilazione dei DLL non è affatto facile perchè:
Non esiste un pulsante magico per tornare indietro, ne esiste uno per generare codice C di merda con nomi di variabili a caso, ma non è un bel bottone
Traduzione di fasterthanlime nel video How does the detour crate work?
Nel caso foste interessati, l’NSA ha sviluppato il suo decompilatore chiamato Ghidra; vi consiglio di darci un occhiata.
Configurazione del client #
Nello scorso articolo abbiamo solo installato il client per Windows, ma non lo abbiamo mai aperto.
Dato che per intercettare la comunicazione dobbiamo avere un client che vada effettivamente ad interrogare il lettore, riapro la mia macchina virtuale con Windows 10 AME e finisco la configurazione del client:
Una volta finita la configurazione (e aver modificato qualche file di configurazione a mano perchè il client comunque non vedeva il lettore nella rete) abbiamo la possibilità di poter richiedere le presenze tramite la rete.
Una volta aperto il client come amministratore, aver premuto il tasto per scaricare i dati e aver aspettato due lunghi minuti, la bellezza di 3543 presenze compaiono sullo schermo.
Qualcosa mi puzza: perchè impiega due minuti a trasferire l’equivalente di un file che pesa poco meno di 200kiB?
Facendo un secondo due calcoli:
$$ \frac{3543\ \textrm{righe}}{120\ \textrm{secondi}} \ \cdot\sim460\ \textrm{bit per riga} = 13.26\ kib/s $$
13kibps di throughput utile su una connessione da 100Mbps? Che schifo!
Non voglio sapere quale disastro di programmazione aziendale italiana può aver causato questo, ma ho come l’impressione che sto per scoprirlo…
The quieter you become… #
Come analizzatore di reti andrò ad installare ed utilizzare Wireshark, uno strumento molto popolare per questo tipo di operazioni.
Una volta installato ed aver aggiunto il nostro utente al gruppo wireshark
possiamo avviarlo ed incominciare a sniffare tutti i pacchetti sulla nostra
interfaccia di rete.
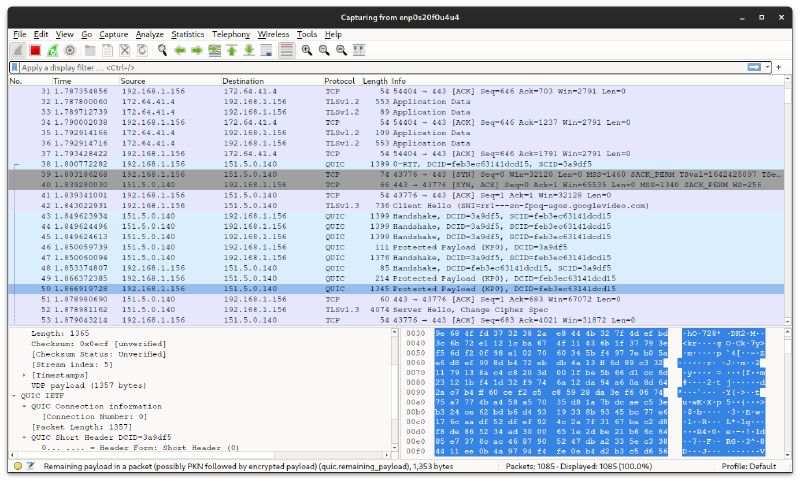
Se è la prima volta che usate uno strumento del genere, potrete accorgervi che anche in una rete locale di piccole dimensioni circolano davvero tanti pacchetti, troppi per essere analizzati uno ad uno.
È proprio qui che entrano in nostro soccorso i filtri: se digitiamo nella barra dei filtri la seguente stringa:
ip.addr == <IP del dispositivo>Vedremmo solo i pacchetti che provengono da o sono diretti verso l’indirizzo IP che abbiamo specificato. Possiamo anche decidere di filtrare il traffico che passa attraverso una specifica porta TCP con:
ip.addr == <IP> && tcp.port == <Porta>Il mondo dei filtri in Wireshark è molto vasto, lascio il link alla documentazione ufficiale per gli interessati.
Una volta fatta partire la registrazione con i filtri corretti possiamo far ripartire un’altra scansione completa delle presenze sul client ufficiale e dovremmo vedere tutti i pacchetti che si scambiano client e dispositivo in tempo reale.
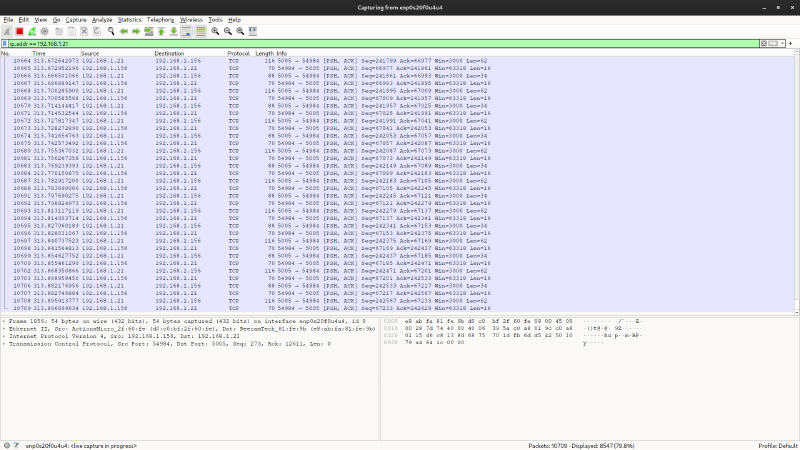
Alla fine del processo abbiamo registrato la bellezza di 14423 pacchetti, che trasportano 3543 presenze. Il tutto diventa ancora più strano…
Dando un’occhiata veloce al traffico possiamo intuire un po’ di cose:
- Nel layer di trasporto viene usato il protocollo TCP sulla porta
5005 - Non viene utilizzato TLS per crittografare i dati, phew
- Ci sono almeno tre fasi:
- Una prima fase di inizializzazione;
- Una seconda fase di scambio di dati nella quale vengono inviati pochi pacchetti ma molto grandi;
- Una terza fase, nella quale vengono inviati moltissimi pacchetti di piccole dimensioni, dove si può intravedere di tanto in tanto il nome dei dipendenti in formato ASCII.
Per studiare più approfonditamente il protocollo avremmo bisogno del solo contenuto dei pacchetti TCP. Qui ci aiuta Wireshark con una funzionalità molto utile.
Se infatti andiamo a selezionare un pacchetto della comunicazione TCP a cui
siamo interessati e premiamo il tasto destro, selezionando Follow > TCP Stream, Wireshark aprirà in automatico il payload di tutti i pacchetti e ci
mostrerà solo il traffico di livello 7.
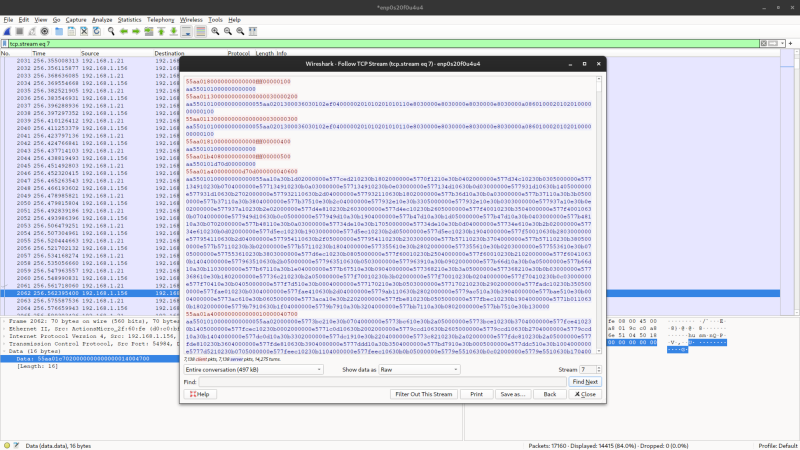
Se andiamo a visualizzare i dati come Raw, Wireshark ci mostrerà i dati
scambiati in formato esadecimale, mostrando in rosso i messaggi inviati dal
client ed in blu le risposte date dal lettore di presenze.
Adesso possiamo copiare le richieste nel nostro text editor di fiducia ed incominciare a studiare il protocollo.
Fuck around and find out #
Ora non rimane che comprendere il protocollo di comunicazione che, sfortunatamente, non è in un formato testuale come l’ASCII o l’UTF-8.
Può sembrare complesso, ma mi ci è voluto solo un pomeriggio per trovare una soluzione abbastanza completa per quello che devo fare.
Richieste #
Le richieste inviate dal client sono tutte lunghe 16 byte e hanno questa struttura:
^55aa([0-9a-f]{24})([0-9a-f]{4})$- I primi due byte sono sempre
55 aa(01010101 10101010in binario); - I 12 byte successivi specificano il comando del client, che d’ora in poi chiamerò “payload”;
- Infine, ci sono due byte little-endian che specificano il numero del
pacchetto, iniziando da
00 00.
Ho notato anche che il server non verifica che gli ultimi due byte siano
inviati in modo sequenziale, quindi possono rimanere a 00 00 per tutto lo
scambio di messaggi.
Risposte #
Le risposte del server invece non hanno una lunghezza fissa e sono divise in due parti, che d’ora in poi andrò a chiamare “header” ed “payload”. L’header è sempre presente ed è lungo 10 byte, mentre il payload può anche essere assente.
Quando il payload è assente il messaggio si comporta come una specie di
null/ACK.
^aa55([0-9a-f]{16})(?:55aa([0-9a-f]+))?$- I primi due byte sono sempre
aa 55(10101010 01010101in binario); - Gli 8 byte successivi sono l’header. Di solito sono
01 01 00 00 00 00 00 00, ma possono cambiare; - Se è presente un payload, il messaggio continua con
55 aa(01010101 10101010in binario); - I byte rimanenti rappresentano il payload.
Ping #
Se vogliamo eseguire un “ping” e verificare che il server risponda possiamo
inviare una richiesta col payload impostato a 01 80 00 00 00 00 00 00 00 00 00 00:
55aa0180000000000000000000000100
aa550101000000000000Il server risponderà poi con un pacchetto senza payload con l’header impostato
a 01 01 00 00 00 00 00 00.
Nome del dipendente #
Sapendo l’ID di un dipendente, è possibile richiedere al server il suo nome
tramite una richiesta con payload impostato a 01 c7 xx xx xx xx 00 00 00 00 14 00, dove xx xx xx xx è un intero a 32 bit little-endian che rappresenta
l’ID del dipendente.
55aa01c7xxxxxxxx0000000014000100
aa55010100000000000055aaxxxxxxxxxxxxxxxxxxxx4c0000000000595a7c7c0000Se l’header della risposta è impostato a 01 00 00 00 00 00 00 00 allora ciò
significa che lo username non è stato trovato, invece se è impostato a 01 01 00 00 00 00 00 00 allora i primi 10 bit del payload rappresentano il nome del
dipendente.
In caso il nome sia più corto di 10 caratteri lo spazio rimanente sarà riempito
con dei caratteri terminatori \0.
Questi messaggi compongono quasi la totailtà della terza fase che ho descritto nel capitolo precedente, quella nella quale vengono inviati tanti piccoli messaggi. Questo fa intuire che il client che prima di tutto fa il dump delle presenze in modo quasi istantaneo , poi aspetta due minuti scaricando per ogni presenza rilevata il nome del dipendente, anche se questo è già stato richiesto in precedenza. Qualcuno insegni il concetto di memoizzazione a questi informatici…
Numero totale di presenze #
Per chiedere quante presenze sono registrate sul dispositivo bisogna effettuare
una richiesta con payload 01 b4 08 00 00 00 00 00 ff ff 00 00:
55aa01b4080000000000ffff00000100
aa550101xxxx00000000Dove xx xx sarà il numero delle presenze salvate rappesentato in un intero a
16 bit little-endian.
65535 richieste massime sembrano un po’ troppo poche, ma immagino che sarà un problema del me del futuro.
Scaricamento di tutte le presenze #
La lista di tutte le presenze va scaricata a blocchi, continuando a chiedere al server dei blocchi da 1024 byte (ovvero 85,333 presenze alla volta) finchè non viene estratto il tutto.
Per fare ciò dobbiamo prima di tutto richiedere il numero totale delle
presenze, poi dobbiamo inviare una richiesta con payload 01 a4 00 00 00 00 xx xx 00 00 00 04, dove xx xx è il numero delle presenze totali
little-endian.
55aa01a400000000xxxx000000040100
aa55010100000000000055aa ...Il server ci risponderà con un payload da 1026 byte, contenente le prime registrazioni seguite da due byte a zero.
Possiamo richiedere un altro blocco da 1026 byte inviando una richiesta con
payload 01 a4 00 00 00 00 00 00 xx xx 00 04, dove xx xx è un intero
little-endian che parte da 01 00:
55aa01a4000000000000010000040100
aa55010100000000000055aa ...Una volta finite le registrazioni il server incomincerà ad inviare dei byte di
padding impostati a ff per arrivare a 1026 byte di payload.
Struttura delle presenze #
Una volta ottenuti tutti i blocchi di registrazioni, possiamo andarli a scomporre in singole registrazioni da 12 byte ciascuno. Non sono riuscito a comprendere per cosa stessero tutti i singoli byte, ma quelli importanti sono questi:
..([26ae]).{5}([0-9a-f]{8})([0-9a-f]{8})- Del secondo byte ci interessano i due bit più significativi per capire se la
registrazione rappresenta un’entrata o un’uscita:
- Se sono
00allora la registrazione è la prima entrata; - Se sono
01allora la registrazione è la prima uscita; - Se sono
10allora la registrazione è la seconda entrata; - Se sono
11allora la registrazione è la seconda uscita;
- Se sono
- I penultimi quattro byte rappresentano l’ID del dipendende (in little-endian);
- Gli ultimi 4 byte rappresentano la data e l’ora della presenza (in little-endian).
All’inizio pensavo che la data fosse rappresentata come una UNIX Epoch, invece a quanto pare ha questo formato (quando rappresentato come big-endian):
- I primi 6 bit rappresentano i minuti;
- I 5 bit successivi rappresentano le ore;
- I 5 bit successivi rappresentano i giorni;
- I 4 bit successivi rappresentano i mesi;
- Infine, gli ultimi 12 bit rappresentano gli anni.
Sospetto inoltre che nei primi quattro byte di ogni presenza siano presenti anche:
- I secondi;
- La modalità di registrazione (se con il PIN, con l’impronta o col badge);
- L’ID del registratore.
Ma dato che non sono campi molto importanti ho deciso che per il momento li lascerò perdere.
Provare col terminale #
Se volessimo provare la comunicazione senza dover scrivere alcun programma che
invia byte su un socket TCP, possiamo utilizzare un po’ di utils di sistema
come netcat e xxd:
# Se usate Bash o Zsh
function send_bytes { echo -n "$3" | xxd -r -p | timeout 1 nc "$1" "$2" | xxd; }
# Oppure, se state usate Fish
function send_bytes -a ip porta dati
echo -n "$dati" | xxd -r -p | timeout 1 nc "$ip" "$porta" | xxd
end
send_bytes 127.0.0.1 5005 55aa0180000000000000000000000100Provando qualche comando preso dagli esempi sopra posso confermare che tutto sembra funzionare correttamente. Nel prossimo articolo vedremo come creare una piccola libreria in Rust per ricavare i dati dal lettore.